
Natural Language Processing (NLP) has witnessed remarkable advancements in recent years, fueled by the convergence of innovative algorithms, abundant data, and computational resources. Among the latest breakthroughs in NLP is the Retrieval Augmented Generation (RAG) model, which represents a significant paradigm shift in how machines comprehend and generate human language. This essay provides a detailed examination of RAG, exploring its architecture, applications, implications, and future directions in the realm of NLP.
Understanding RAG
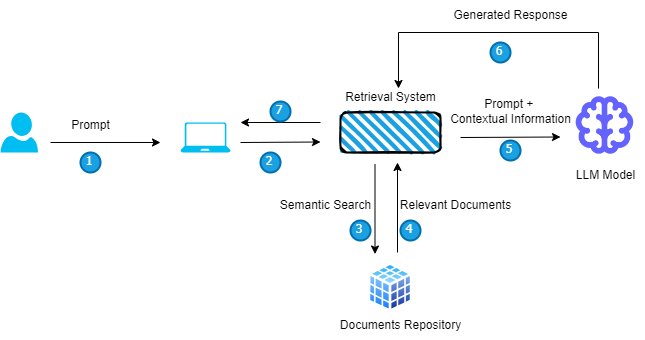
At its core, RAG is a hybrid model that seamlessly integrates retrieval-based and generative approaches to NLP. The model consists of three key components: a retriever, a reader, and a generator. The retriever efficiently gathers relevant information from large knowledge sources, such as databases or the internet. The reader component processes and understands the retrieved passages, extracting essential information. Finally, the generator leverages this distilled knowledge to produce coherent and contextually relevant responses or outputs. By combining the strengths of both retrieval and generation, RAG overcomes the limitations of traditional models and achieves more nuanced language understanding and generation.
RAG operates on a deceptively simple principle: it seamlessly combines retrieval and generation.
The Retrieval Stage
Imagine a student preparing for an exam. The LLM acts as the student, possessing a vast vocabulary and knowledge of grammar. RAG, on the other hand, plays the role of a diligent study partner. When presented with a prompt or question, RAG delves into external knowledge sources, like web documents or databases. Using sophisticated retrieval techniques, RAG meticulously searches for the most relevant information that aligns perfectly with the user’s query.
Here’s a closer look at the retrieval process:
- Understanding the Intent: RAG employs natural language processing (NLP) techniques to grasp the user’s intent behind the prompt or question. This involves analyzing keywords, sentence structure, and the overall context.
- Identifying Relevant Sources: Based on the extracted intent, RAG scours external knowledge sources, prioritizing reliable and up-to-date information. These sources can be vast and diverse, encompassing web documents, news articles, research papers, or even domain-specific knowledge bases depending on the application.
- Ranking and Filtering: Not all retrieved information is created equal. RAG employs ranking algorithms to prioritize the most relevant and informative pieces based on their alignment with the user’s query. Additionally, it filters out irrelevant or outdated information, ensuring the quality of the retrieved knowledge.
The Generation Stage
Once RAG has gathered the most relevant nuggets of information, it’s time for the LLM to shine. Equipped with this retrieved context, the LLM steps in:
- Leveraging Retrieved Knowledge: The LLM doesn’t simply regurgitate retrieved information. Instead, it intelligently integrates this knowledge into its generation process.
- Building a Cohesive Response: By drawing upon its understanding of language structure and the retrieved context, the LLM crafts a response that is not only grammatically sound but also factually accurate and informative.
Think of it as the student, armed with the knowledge meticulously gathered by their study partner (RAG), formulating a well-structured and insightful answer to the exam question. The combined efforts of both the LLM and RAG lead to a superior outcome.
Architecture Overview
The architecture of RAG is modular and flexible, allowing for adaptation to various NLP tasks and domains. The retriever component employs techniques such as dense retrieval or sparse retrieval to efficiently retrieve relevant passages. These passages are then fed into the reader component, which utilizes pre-trained language models like BERT or RoBERTa to comprehend the text and extract key information. Finally, the generator component, often based on transformer architectures like GPT, synthesizes the retrieved knowledge into coherent responses. This modular design not only enhances performance but also facilitates scalability and extensibility.
The Advantages of RAG
RAG offers a multitude of benefits for LLM-powered applications:
- Enhanced Factual Accuracy: LLMs trained on massive datasets can sometimes generate outputs riddled with factual inconsistencies. RAG mitigates this issue by grounding the LLM in reliable and up-to-date information from external sources. This ensures that the generated text reflects true-world knowledge, fostering trust and credibility.
- Reduced Fine-Tuning Needs: Fine-tuning involves meticulously adjusting an LLM’s parameters to improve its performance on specific tasks. This process can be time-consuming and resource-intensive. RAG acts as a powerful alternative, allowing LLMs to access and leverage external knowledge without extensive fine-tuning. This translates to faster development cycles and more efficient use of resources.
- Unlocking Complex Tasks: RAG empowers LLMs to tackle intricate tasks that require access to factual knowledge beyond their training data. Imagine a question-answering system that can delve into scientific research papers or a report generation tool that seamlessly integrates financial data. RAG unlocks doors for a wider range of LLM applications, pushing the boundaries of what’s possible.
Applications of RAG
RAG demonstrates remarkable versatility across a wide range of NLP applications:
Question Answering: In question answering tasks, RAG excels at providing accurate and informative responses by leveraging its retrieval and generation capabilities. Whether answering factual queries or complex inquiries requiring synthesis, RAG consistently outperforms traditional models.
Conversational Agents: RAG-powered conversational agents offer more engaging and contextually grounded interactions with users. By integrating retrieved knowledge into conversations, these agents provide richer and more informative responses, enhancing user experience and satisfaction.
Document Summarization: RAG’s ability to retrieve and generate content makes it well-suited for document summarization tasks. By distilling key insights from lengthy documents, RAG facilitates efficient information comprehension and decision-making.
The Future of RAG
The realm of RAG is constantly evolving, with researchers exploring ways to further enhance its capabilities. Here are some exciting possibilities on the horizon:
- Improved Retrieval Techniques: Advancements in natural language processing (NLP) can lead to even more sophisticated retrieval methods. Imagine RAG employing advanced reasoning techniques to not only identify relevant information but also understand the relationships between different pieces of knowledge. This would allow RAG to provide a more nuanced and comprehensive understanding of the user’s query.
- Customizable Knowledge Sources: The ability to integrate domain-specific knowledge bases into RAG systems can further enhance their accuracy and effectiveness in specialized fields. Imagine a legal research assistant powered by RAG that can delve into legal databases and case studies, providing lawyers with highly relevant and up-to-date information.
- Lifelong Learning LLMs: Currently, LLMs are trained on static datasets. However, the future holds promise for LLMs that can continuously learn and update their knowledge. This would allow RAG to integrate the latest information from external sources, ensuring that generated outputs remain factually accurate and reflect the ever-evolving world.
Ethical Considerations
As RAG-powered systems become more ubiquitous, addressing potential biases and ethical considerations is crucial:
- Bias in Retrieved Information: External knowledge sources can harbor biases, which can be inadvertently amplified by RAG. It’s essential to develop techniques for identifying and mitigating bias in retrieved information to ensure fair and responsible use of RAG systems.
- Transparency and Explainability: Understanding how RAG arrives at its outputs is crucial. Future developments should focus on providing transparency into the retrieval process and the reasoning behind the generated text. This fosters trust and allows users to critically evaluate the information presented.
Conclusion
Retrieval Augmented Generation (RAG) represents a significant leap forward in the realm of large language models. By enabling LLMs to access and leverage external knowledge, RAG paves the way for more accurate, informative, and versatile AI-powered applications. As RAG continues to evolve, it holds immense potential to transform the way we interact with AI systems and unlock a new era of intelligent text generation. From enhancing communication through chatbots to fostering deeper learning with question-answering systems, RAG’s possibilities are vast and ever-expanding. By addressing ethical considerations and continuously pushing the boundaries of retrieval techniques, RAG promises to be a cornerstone of a future powered by reliable and informative AI.